
Practice with strings
These are several examples that will help you practice decomposition when writing functions that use strings.
Decomposition is a fundamental skill, so we want you to have lots of practice with it!
Splitting blocks of letters
You are given as input a string that contains repeating letters:
'AAAAABBCCCDDDDDDDEAAAA'You need to break it into a list that has blocks of repeating letters:
['AAAAA','BB','CCC','DDDDDDD','E','AAAA']Drawing it out
Let’s draw out how this would work:
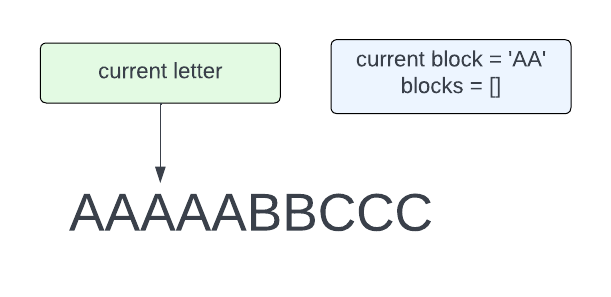
We are going to be looping through all of the letters in the string, so let’s say we are currently looking at the third A. We need to keep track of the block of letters we have seen so far, so this is shown as current block = 'AA'. We also need to keep track of all of the completed blocks we have seen. This is in blocks, which is currently an empty list.
Since we are looking at A, and this is the same as the current block, we should append A to the current block and move to the next letter.
Let’s show a later step:
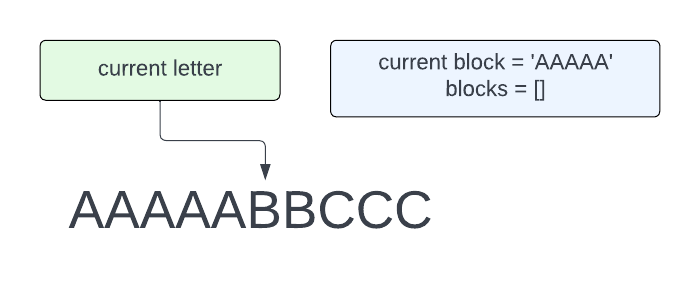
Now the current letter is the first B. We have accumulated all of the As in the first block, so current block = 'AAAAA'.
At this point, we need to recognize that B is not the same letter as what we are storing in our current block. That means that we need to append the current block to the list of blocks and then reset current block so it has just B in it.
Here is one more later step:
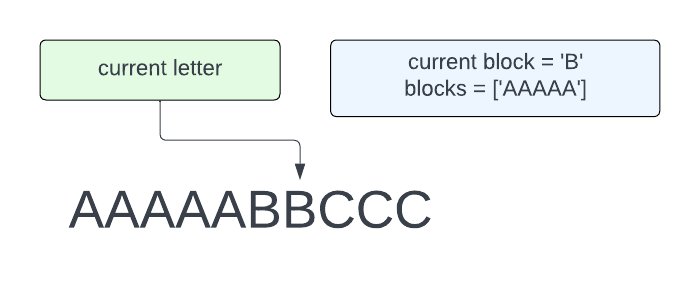
Now we are pointing to the second B. We have moved 'AAAAA' into the list of blocks, and our current block is B. Since we are looking at another B, we can append this to the current block.
An algorithm
Here is an English description for this algorithm:
- set the current block to None
- set the list of blocks to []
- loop through all of the letters in the string
- if the current block is None
- start a new block by setting current block equal to this letter
- else if the current letter is in the current block
- append the current letter to the current block
- else
- append the current block to the list of blocks
- start a new block equal to this letter
- if the current block is None
- append the current block to the list of blocks (special case to handle the last block)
- return the list of blocks
The code
Here is the code for this algorithm:
def split_blocks(text):
blocks = []
current_block = None
for char in text:
if current_block is None:
# Start first block
current_block = char
elif char in current_block:
# Extend block
current_block += char
else:
# New block
blocks.append(current_block)
current_block = char
blocks.append(current_block)
return blocks
print(split_blocks('AAAAABBCCCDDDDDDDEAAAA'
))Testing the code
If you have put the code for split_blocks into a file called split_blocks.py, then you can create a test file called test_split_blocks.py. Here is an example of some tests:
from split_blocks import split_blocks
def test_split_blocks():
result = split_blocks('AA')
assert result == ['AA']
result = split_blocks('AAAAABBCCCDDDDDDDEAAAA')
assert result == ['AAAAA', 'BB', 'CCC', 'DDDDDDD', 'E', 'AAAA']Grouping customers
Your customers often come in as family groups. You have a list of customer family names (for now we’ll assume that all members of a family have the same family name), and you want to group those customers together so they can be served as a group instead of individually. You also want to know how many people are in each group.
Given a list of family names, print out the sequence of family names along with the number of individuals in each family.
For example, this input:
['Smith', 'Smith', 'Smith', 'Smith', 'Ng', 'Ng', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Santos', 'Kowalska', 'Kowalska', 'Kowalska', 'Smith', 'Smith', 'Smith']should produce this output:
Smith: 4
Ng: 2
Nelson: 12
Santos: 1
Kowalska: 3
Smith: 3An algorithm
This is very similar to the above problem! Instead of going through a string we are going through a list. As we look at the current name, we need to decide if it matches the current group. Here is an algorithm:
- set the current group to None
- set the list of groups to []
- loop through all of the names in the list
- if the current group is None
- start a new group by setting current group equal to a list containing this name
- else if the current name is in the current group
- append the current name to the current group
- else
- append the current group to the list of groups
- start a new group equal to a list containing this name
- if the current group is None
- append the current group to the list of groups (special case to handle the last group)
- return the list of groups
The code
Here is code for this algorithm:
def group_customers(customers):
groups = []
current_group = None
for name in customers:
if current_group is None:
# Start first group
current_group = [name]
elif name in current_group:
# Extend current group
current_group.append(name)
else:
# Start new group
groups.append(current_group)
current_group = [name]
groups.append(current_group)
return groups
def format_groups(groups):
report = []
for group in groups:
report.append(f'{group[0]}: {len(group)}')
return report
def generate_customer_report(customers):
groups = group_customers(customers)
report = format_groups(groups)
return reportThe group_customers() function does everything in the algorithm. The result of this function is a list of lists! To see how this is true, we are keeping track everyone with the same name in current_group, which is a list:
current_group = ['Smith', 'Smith', 'Smith']When we need to create a new group, we append this to a list of groups, called groups:
groups = [['Smith', 'Smith', 'Smith']]If we next look at 'Nelson', then we will have current_group = ['Nelson', 'Nelson]. When we add this to groups, we get:
groups = [['Smith', 'Smith', 'Smith'], ['Nelson', 'Nelson']]We have a list of lists!
The format_groups() function takes this data and puts it into a new list of the format we need for output:
[name: number_in_the_group]It can get a name by using group[0] and it can get the number of people in the group using len(group).
We can run this code with:
customers = ['Smith', 'Smith', 'Smith', 'Smith', 'Ng', 'Ng',
'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson',
'Nelson', 'Nelson', 'Nelson', 'Nelson', 'Nelson',
'Nelson', 'Nelson', 'Santos', 'Kowalska',
'Kowalska', 'Kowalska', 'Smith', 'Smith', 'Smith']
report = generate_customer_report(customers)
for line in report:
print(line)Testing the code
If you have put the code for this problem into a file called customer_report.py, then you can create a test file called test_customer_report.py. Here is an example of some tests:
from customer_report import group_customers
customers = ['Smith', 'Smith', 'Smith', 'Nelson', 'Nelson']
def test_group_customers():
groups = group_customers(customers)
assert groups = [['Smith', 'Smith', 'Smith'], ['Nelson', 'Nelson']]